

背景:业务使用springboot框架,前端使用的nginx再并发量大的时候出现后端异常告警。
资源配置:服务端 单节点 4c16g nginx 2c4g 中间件seata 2c8g 后端数据库 rds2c8g,默认连接6000
压测工具:jemerter性能测试 单接口1000并发压测,多接口串联500并发压测
出现问题:
1、压测提示报错,系统异常

2、服务日志报错

3、压测过程中提示

4、nginx返回报错

5、服务生产环境,日常提示告警内容包含关键词java.util.concurrent.TimeoutException、java.sql.SQLException
处理过程:
调整后端服务对应的连接参数
根据压测结果和服务日志报错结果进行后端服务的连接参数排查,考虑到jdbc的连接参数和dubbo的参数配置问题。于是修改java应用对应参数如下:
| at java.net.SocketInputStream.socketRead0(Native Method) at java.net.SocketInputStream.socketRead(SocketInputStream.java:116) |
|---|
其中尝试调整的参数有:
1、尝试修改数据库超时时间,问题暂未解决;
2、尝试修改seata超时时间,问题暂未解决;
3、尝试修改中间件DUBBO超时时间,问题暂未解决;
4、尝试分析中间件参数,发现DUBBO使用默认配置,尝试修改线程数,问题解决,修改参数如下:
| dubbo: protocol: port: -1 # 协议端口。使用 -1 表示随机端口。 name: dubbo threads: 500 |
|---|
当压测的并发数再往上提的时候又出现问题,于是
1.重新启动一个seata服务,与生产配置保持一致;
2.调整seata配置参数如下:
| retry-times: 40 # 试获取全局锁时的最大重试次数为40 默认30 retry-interval: 50 # 每次重试之间的等待时间50ms 默认10ms retry-policy-branch-rollback-on-conflict: true # 发生锁冲突时回滚分支事务 500条失败率为0 |
|---|
nginx的参数调整
根据报错日志,可以判断是因为nginx的连接数不够导致,默认nginx的worker 线程连接数是1024
javax.net.ssl.SSLHandshakeException: Remote host terminated the handshake
at sun.security.ssl.SSLSocketImpl.handleEOF(SSLSocketImpl.java:1511)
at sun.security.ssl.SSLSocketImpl.decode(SSLSocketImpl.java:1328)
at sun.security.ssl.SSLSocketImpl.readHandshakeRecord(SSLSocketImpl.java:1233)
at sun.security.ssl.SSLSocketImpl.startHandshake(SSLSocketImpl.java:417)
at sun.security.ssl.SSLSocketImpl.startHandshake(SSLSocketImpl.java:389)除去日常使用的连接,在并发压测的时候肯定是扛不住的。于是将nginx的默认配置worker_connection调整为10000

再次进行压测不再提示如上报错,问题解决
其中也还针对前端的入口进行了一些keepalive的超时时间配置,但是那些超时配置默认的已经完全够用,如果超时时间超过60s还不能返回数据的话,这个对于ng是一个巨大的压力,说明后端服务肯定出问题了
seata中间件参数调整
1、选择seata中间件及其版本的理由
我们的业务有一个数据的动账调整,因为之前服务各接口之间的结算都是走事务,而且事务控制的不是特别好,导致了线上数据的很多不一致问题。于是引入了seata中间件,用于满足接口间对于数据处理的事务完整性。
根据我们spring boot的框架使用的版本,我们选择seata 1.6的版本
我们spring boot的框架版本是2.7.18。


对应版本选择可以参考https://wenku.csdn.net/answer/4nqrho8zwh
2、服务日志报错一直提示的java.sql.SQLException: io.seata.core.exception.RmTransactionException: RPC Timeout
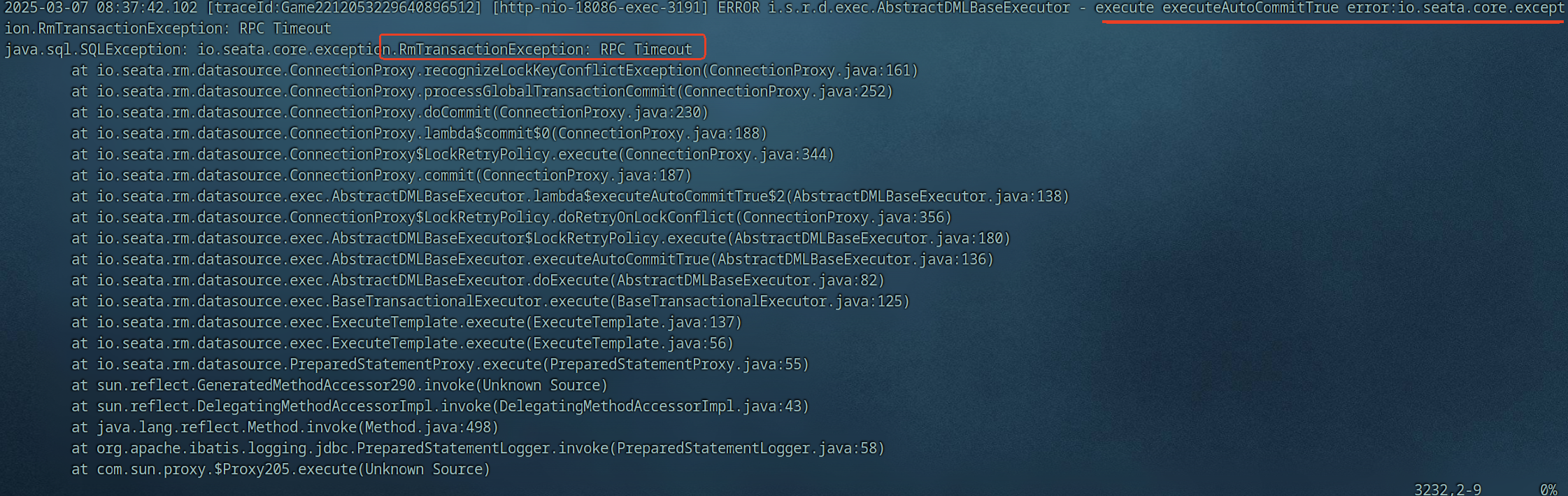
1、通过seata官方文档查找和一系列推敲,最后定位到了如下几个参数
| # 数据库初始连接数 默认1 store.db.minConn=500 # 数据库最大连接数 默认20 store.db.maxConn=1000 # 获取连接时最大等待时间 默认5000,单位毫秒 store.db.maxWait=15000 # 查询全局事务一次的最大条数 默认100 store.db.queryLimit=10000 |
|---|
| #对于批量请求消息的并行处理开关,1.6.1 默认为 true,建议为 false,1.6.1 中存在并行处理时数组越界异常 server.enableParallelRequestHandle=false #TC 批量发送回复消息开关,建议为 true,可解决 client 批量消息时的线头阻塞问题 transport.enableTcServerBatchSendResponse=true |
|---|
2、还有一个需要注意的点:因为seata采用的docker +db的高可用部署模式,通过nacos作为配置中心,直接在nacos中修改配置文件之后需要重启seata才能生效

问题解决后效果:
单接口1000并发压测通过

5个接口串联进行500并发压测,通过

总结:
在出现这种问题的时候需要潜下心来好好的排查,查阅官方文档,然后采用各种不同的姿势进行测试。其中我们就尝试了更换服务器节点,做分布式部署等措施虽然最后证明是无效的动作。但是整体排查过程还是需要考虑更多的可能性。dd
